
����ǰ����Ҫ��[@AK-48] [[��ש����]ʹ��״̬���Ͷ�̬�滮ʵ������ַ�(�Լ�APL)���Զ�����]
����AK-48�����Ѿ������ȷ���Ե�״̬ת�ơ�������MDP����˲�ȷ��״̬ת��(�������Ч��)��
��������һ��״ִ̬����ͬ�������ܻ�������ת�Ƶ���ͬ�ĺ��״̬�����Բ���ʹ������ͼ������ϵͳ������ʹ��[�����ɷ���]���档
�������MDP���������ͼ��ͬ������˼����Ȼ�Ƕ�̬�滮��������ķ�����������
����������ͼ�У�һ��״ִ̬��һ��������ȷ����ת�Ƶ�һ�����״̬�������� ����ʾ״̬ת�ƺ���������s�ǵ�ǰ״̬��a��ѡ��Ķ�����s'�Ǻ��״̬��
����ʾ״̬ת�ƺ���������s�ǵ�ǰ״̬��a��ѡ��Ķ�����s'�Ǻ��״̬��
�����������ϵͳ������Ҫ״̬ת�ƺ���������Ҫ�����溯��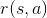 ����ʾ��s״ִ̬��a�����õ�����������(����DPS��˵��������ɵ��˺�)��
����ʾ��s״ִ̬��a�����õ�����������(����DPS��˵��������ɵ��˺�)��
�������ǿ�����ֵ�������������ͼ��������ֵ�������̣�

����ʽ��As��ʾ�ڵ�ǰ״̬s�ܹ�ִ�еĶ������ϡ�Uk(s)��ʾ��s״̬��������k��״̬ת�����ܵõ���������档
�������ݴ˷��̣����Խ���ֵ��������
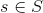 ������ֵ�������̣�����Uk+1(s)��ֵ��
������ֵ�������̣�����Uk+1(s)��ֵ����������ʱ��״̬s�µ����Ų��ԣ���ִ��ʹֵ��������ȡֵ���Ķ���a��
�������벻ȷ��״̬ת�ƺ��״̬�뵱ǰ״̬×���������Ǻ�����ϵ��������״̬ת�Ƹ��ʺ���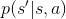 ������״̬ת�ƺ������˺�������Ϊ��s״ִ̬�ж���a����״̬s'�ĸ���Ϊp��
������״̬ת�ƺ������˺�������Ϊ��s״ִ̬�ж���a����״̬s'�ĸ���Ϊp��
�������ڵ��ﲻͬ�ĺ��״̬���ܵõ���ͬ����������(������Щ�ɱ���������Ч��)���������溯��Ҳ���Ϊ���� ��
��
������s��������k��״̬ת�����ܵõ���������棬�����ɴ�s��������״̬s'ת�ƺ�õ�������������ʼ�Ȩƽ��ֵ(����ֵ)����ʾ��
������ʱֵ��������Ϊ��
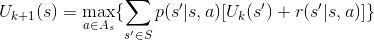
����ֵ�����㷨û�з����仯����ȷ����״̬ת�Ƶ������ͬ��
���������е��˺����������һ�������еĹ��̣�û�н�ת��(��նɱ->նɱ)��û����ʼ��Ҳû���սᡣ�����ֵ���������Ǿ����̶���H��״̬ת�ƺ�ͽ����㷨��������ϣ���ܹ������������˺����������������DPS��
�����������˺�������̵��ۻ�����(���˺���)��ʱ�����Ŷ��������ӣ��Ƿ�ɢ�ģ�������������һ��˥������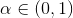 ʹ��������
ʹ��������
����˥�����ӵ�����������ʼ״̬(t=0ʱ)1���˺��ļ�ֵ��1�����ڽ���һ��״̬ת�ƺ�(t=1ʱ)1���˺��ļ�ֵ����Ϊ������������״̬ת�ƺ�(t=2ʱ)1���˺��ļ�ֵ����Ϊ��2���������Ǿ�����һ����������ֵ����ʾ�ۻ���������
������ʱֵ�������̱�Ϊ��
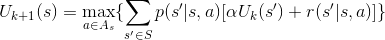
����ֵ�����㷨��Ϊ��
������ֵ�������̣�����Uk+1(s)��ֵ������˥�����Ӧ����ȡ���㹻���㷨�ͻ�������ʹ��������(����DPS)���
����������㷨��Ȼ��ȫ��DPS������ȫ�濼�ǣ�������ʱ����ɵ��˺���õ��ϸߵ����ۣ�������ʱ����ɵ��˺���õ��ϵ͵����ۡ��������˥������ȡ�ò�ǡ�����㷨��������ɱ��ȡ�ѡ��ľ���������ڸ��˺����������档
����������ö�̬��˥�����ӣ����Խ��ۻ�����������DPS����ô�㷨��Ȼ��ʹDPS�����������Щ�˺������ĸ�����ɵġ���Ȼ������Ҫ��������������
������������������Ҫ����˥�����Ӧ��ͦ¡�ֵ��������Ϊ��
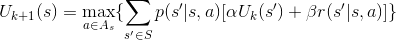
��������
��������������㾫���㹻�ߣ��㷨�������˺�������ʱ�̣���ֻ�����˺������Ĵ�С��
����������һ�ݿ�ս��ʵ�� [https://github.com/AeanSR/maga/blob/master/mdp.cpp]����ģ�ͼ�(�ر�����С״̬�ռ�dz���Ҫ)�����ǿ��Եõ�������������Ľ����
�������к��㷨����Ľ����״̬�������ĺ��������г����кϷ���״̬������ע����Щ״̬����Ӧ��ִ�еĶ�����
������ȡ�����һС�������£�
����RBST 0, BSST 0, ERRM 0, BTCD 0, RAGE 0 - bt 30252.371
����RBST 1, BSST 0, ERRM 0, BTCD 0, RAGE 0 - bt 30560.494
����RBST 2, BSST 0, ERRM 0, BTCD 0, RAGE 0 - bt 30862.881
����RBST 0, BSST 1, ERRM 0, BTCD 0, RAGE 0 - bt 30522.141
����RBST 1, BSST 1, ERRM 0, BTCD 0, RAGE 0 - bt 30829.566
����RBST 2, BSST 1, ERRM 0, BTCD 0, RAGE 0 - bt 31130.418
����RBST 0, BSST 2, ERRM 0, BTCD 0, RAGE 0 - bt 30790.562
����RBST 1, BSST 2, ERRM 0, BTCD 0, RAGE 0 - bt 31095.748
����RBST 2, BSST 2, ERRM 0, BTCD 0, RAGE 0 - bt 31380.145
����RBST 0, BSST 0, ERRM 1, BTCD 0, RAGE 0 - bt 30278.369
����RBST 1, BSST 0, ERRM 1, BTCD 0, RAGE 0 - bt 30586.496
����RBST 2, BSST 0, ERRM 1, BTCD 0, RAGE 0 - bt 30888.879
����RBST 0, BSST 1, ERRM 1, BTCD 0, RAGE 0 - ws 30592.404
����RBST 1, BSST 1, ERRM 1, BTCD 0, RAGE 0 - ws 30909.021
����RBST 2, BSST 1, ERRM 1, BTCD 0, RAGE 0 - ws 31202.273
����RBST 0, BSST 2, ERRM 1, BTCD 0, RAGE 0 - ws 30860.826
����RBST 1, BSST 2, ERRM 1, BTCD 0, RAGE 0 - ws 31176.746
����RBST 2, BSST 2, ERRM 1, BTCD 0, RAGE 0 - ws 31467.826
��������һ�ν�����ǿ��Կ�������ͬ��ŭ��Ϊ�㣬��Ѫ���õ�����£�
�������û�м�ŭ����Ӧ�ô���Ѫ
��������м�ŭ��Ѫӿ���>��Ѫ
�������书��һ�ۣ�ֱ����ȡ���Ų��ԡ�������ǿ��
�������Զ����ܹ�����MDP�����С��ģ���⣬MDP���GA���ָ��á�
����MDP����������״̬�ռ��ά�����ѡ�ÿ����һ��״̬����״̬�ռ����Ҫ��һά������״̬�ռ�ijߴ��ʧ�ء��������Dz��ܰѾ�ȷ��ģ�ͱ��Ƴ�MDP��ֻ������ģ�͡�
�������⣬�������״̬�ռ���ÿһ��״̬��Ӧ��ִ�еĶ���������һ�������ֵ䣬����APL�����������Ȼ������Ϊ�Ϸ���APL�ṩ��ģ������������ӷ��ģ����������(���ʵ�ֵ����������3MB)��
��������Ҳֻ��ѡ���Եز������и���Ȥ�IJ��֣����ѽ����ȫ���Ķ������⡣��Ҳ��MDPӦ���ϵ�һ�����ơ�











 6.2��Ѷ��6.2����˵�� | �汾ר�� | �������� | һ�ɵ�ħ���� | ʱ������ | ʱ��������� |
6.2��Ѷ��6.2����˵�� | �汾ר�� | �������� | һ�ɵ�ħ���� | ʱ������ | ʱ��������� | Ҫ���ر���Ӧ����в���� | ��ӻ�ȡָ�� | Ҫ��ģ���� | ����ԭ������ | �������� |���� ��� ���� |
Ҫ���ر���Ӧ����в���� | ��ӻ�ȡָ�� | Ҫ��ģ���� | ����ԭ������ | �������� |���� ��� ���� | �������ݣ����ɰ����� | ������ | ��˵��ָ������ | ���¾����� | ʷʫ���³� |����ϻ���
�������ݣ����ɰ����� | ������ | ��˵��ָ������ | ���¾����� | ʷʫ���³� |����ϻ���  ��5�˱���Ѫ鳿� |
ͨ��� |
�½�� |
������ͷ | Ӱ��Ĺ�� | ��ʯ�ϲ� |
��ï�ֵ� |
�ֹ쳵վ
��5�˱���Ѫ鳿� |
ͨ��� |
�½�� |
������ͷ | Ӱ��Ĺ�� | ��ʯ�ϲ� |
��ï�ֵ� |
�ֹ쳵վ ���Ŷӱ����������� | ��ʯ���쳧 | ��鳱� | Ѫħ | ������ | ��˹�� | а�����¡ |
���Ŷӱ����������� | ��ʯ���쳧 | ��鳱� | Ѫħ | ������ | ��˹�� | а�����¡ |  רҵ���ܣ����� |
��ҩ |
��Ƥ |
�ɿ� |
��� |
���� |
�÷� |
��Ƥ |
���� |
��ħ |
�鱦 |
���� |
���� |
����
רҵ���ܣ����� |
��ҩ |
��Ƥ |
�ɿ� |
��� |
���� |
�÷� |
��Ƥ |
���� |
��ħ |
�鱦 |
���� |
���� |
����





