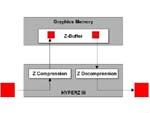
| R300硬件全分析 |
| --R300比上一代更高级的Programs Vertex Shader与Program
Pixel Shader |
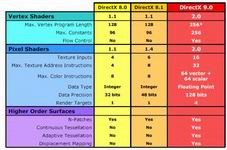 |
| [DX之间的对比表格] |
在DX8中,微软提出了Programs Vertex Shader 1.2与Program Pixel Shader 1.1-1.4,微软对于图形发展的可编程性的支持与推动不遗余力,然而在这中间微软却忽略了市场对于显卡功能性的需求,PVS与PPS对硬件与软件都提出了前所未有的严格要求,打个比方如果一款游戏想要全面利用PVS和PPS的话就要放弃一些较为传统的设计方案,但这样又造成了游戏与中低档显卡的不兼容甚至不同显卡在支持PVS和PPS上都有一些不同,所以大部分的厂商只将PVS与PPS做为一种额外的特效来支持,并没有全面的普及。即使这样,微软还是铁了心的发布它们的PVS与PPS,在DX9中PVS与PPS都发展到了2.0版本。先让我们来看看在处理规格上DX8、DX8.1、DX9之间有些什么差别。 |
|
很明显,微软公司做了极大的升级调整,Vertex Shaders 2.0相比之前的1.0版本,所能接受的最大处理规格更加的多,并且复杂与精确。比如在DX8体系中对于顶点效果器的编程最大的限制指令长度是128条,然而到了DX9中却升级为256条,实际上这还可以通过Loop缩环回路实现最大1024条指令,更多的指令数处理上升意味着R300可以在同一周期内处理更多的单顶点光源或者更多的矩阵转换或者实现更多精彩的效果,当然对于越来越懒惰的PC游戏开发商们来说,256条指令或者1024条指令对于它们来说并不会有太多的影响,所正PC上的3D游戏看来看去都是那样的画面不是嘛?除了顶点效果器的指令长度和常数指令有了较大的提升之外,2.0版本的Vertex
Shader的另一大特色是增加进了流程的控制,包括了上面提到的循环、跳转、子程序调用这些类似于C语言中很基础的流程方式,更具体的还有ADD,DP3,DP4,EXP,FRAC等等[有兴趣的话可以参考ATi的HardwareShading_2002_Chapter3-1.pdf白皮书],这些编程的函数性使它看起来更像一颗可以编程的图形芯片,不是嘛?因为在以前的Vertex
Shader版本中,如果想要将不同的纹理与不同的光源混合在一起的话就需要单独写一段Shader效果器的程序来,这意味着每一次混合就要调用一段的程序代码。而在Vertex
Shader 2.0中却不需要这样用,开发者只需将色彩,方向,光源等等这些自定义值写入子程序中直接调用即可。 |
 |
 |
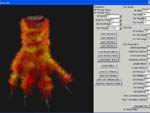
| [ATi提供的,演示动物茸毛的Demo,通过在子程序中写入自定义值即可实现最后的生成效果,其中包括了Fin皮肤鳍状形体与茸毛细节纹理] |
|
| [Fuzzy茸毛效果的放大图,据ATi的工作人员表示在三年前当时最顶级的显卡完成这样的渲染需要耗时大约十几个小时,而ATi现在能做到Real-Time实现渲染] |
|
|
 |
 |
| 1、[先将正常的多边形依据每条边缘法线的方向进行一定的移动操作---称之为Shell外壳生成] |
|
| 2、[增加额外更多的多边形同样依据边缘法线的方向进行突出伸长的步骤---称之为Fins鳍状生成] |
|
|
|
|
nVIDIA在GeForce4 Ti系列加入了两条的Vertex Shader流水线,这样当3D程序在GF4
Ti的2个Vertex Shader进行三角形的顶点坐标转换工作的时候,相较传统的T&L就能节省大约一半的时间,依我们前文中提到每个顶点的转换需要四条指令的运作。
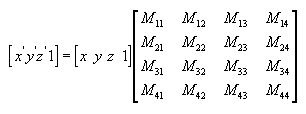
[实际上一个三角形的生成就是顶点坐标转换的乘法运算] |
| 而ATi为R300加装了4条的Vertex Shader流水线,这样只要在一个单周期时钟频率,也就是1MHz内4条流水线同时开动,就能完成一个三角形顶点位置的转换,这意味着Radeon9700拥有325M/s的三角形生成能力,当然这样的处理也包括128bit的双精度诉求,GeForce4
Ti4600大约为136M/s,GeForce3 Ti500为60M/s,Radeon 8500则是68M/s。 |
 |
 |
|
[ATi R300的4条
Vertex Shader流水线]
|
|
|
|
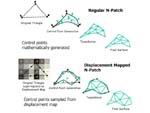 |
[新一代的N-Patch概念
Truform 2.0更加的灵活] |
每条流水线中还包含了一个32bit的标量处理器与128bit的矢量处理器,简单一点的说就是数量是对数据处理的选择采用一个一个的数据不同值的对比运算处理,矢量是对一组数据同时处理的方式负责诸如坐标X,Y,Z,W等组合型的数据流,在Vertex
Shader ALU处理中,除了Loop Counter这项操作是用标量方式之外,大部分都采用矢量的处理方式。 |
ATi从R200开始就力推它们的N-Patch特性,虽然这是一项任重而道远的工作,但ATi显然还是乐此不疲。在DX9也包括了Truform
2.0的支持,它在操作方法上与上一代的Truform没有太多的不同,只是在其中的关键操作Tessellation棋盘型嵌入上显得更加灵活,之前的Radeon8500限定了Truform只能采用在固定的8个等级中进行调整的方案,就好像如果设定了4级的Truform的话那么无论远景或是近景都将一律的采用4级的嵌入,这就造成了在一些游戏中出现了模型的变形与不符合现实的画面出现,例如在Serious
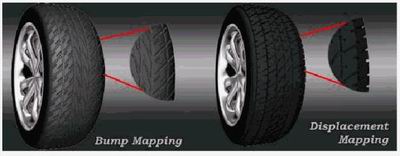
Sam中的变形的圆形枪体,在Truform 2.0中将不会再出现这种现象,它会根据3D场景的远近自适应的判断该用哪一种等级又或者不采用嵌入的操作。除此之外新的TruForm中还包含了Displacement
Mapping功能,对于此功能之前我们在介绍Matrox Parhelia的技术文档中有关相当的描述在此就不再重复,但是我想提出的一个看法是Displacement
Mapping并不真的可以像Matrox所说的那样,可以完全代替三角形构模法。实际上它很难独立地做出精细的立体模型,所以我更偏向ATi对于Displacement
Mapping的定义:能够在3D对象与外形的表面上提供更多的控制,从特殊种类贴图取样值来进行顶点位置的修改,视觉效果类似Bump
Mapping,但是比Bump Mapping更逼真与细致。
 |
| [ATi对于Displacement Mapping用途的定义与Matrox有些不同] |
|
| OK,现在轮到ATi R300的另一个精髓部分了--Pixel Shader,很可惜Pixel
Shader 2.0似乎并没有Vertex Shader 2.0进步的那么大,它并不支持流程控制,所以对于编程人员来说,应用它是件复杂的工作过程,但是对我们最终用户来说却没有什么不同之处。 |
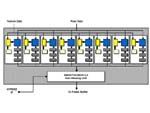 |
| [Pixel Shader流水线] |
R300始无前例的整合了8条像素Pipeline流水线,这在半年前还是不少人梦想中的事,现在却成为了事实。每一条流水线上只包含了一个的纹理元素渲染器,这样ATi在单纹理渲染与多层纹理渲染的理论性能值上是一样的,可能你会对这样的设计在外理多层纹理时的性能是否相较当前流行的单流水线双纹理单元的性能的提升持有一些怀疑的意见,实际上这样做在处理多层纹理时的性能的确提升的并不明显,但这并不是ATi的错,而是受限于当前的存储介质。如果ATi再增加一个纹理元素渲染单元的话,256bit的显存位宽将无法满足纹理传输的需要,所以装了也是白装。当然我们认为如果再加多一个纹理渲染TMU单元的话,对于Die的空间或许也是一个挑战。所幸的是ATi同样可以通过以循环的方式进行重复性的纹理贴图,这在上一代的显卡中已经被广泛的采用,所以并不用太担心只有单个的纹理渲染单元会耗掉你太多的渲染时间,我们认为如果ATi在将来设R350的时候,如果采用了DDRII的显存模块,那么将可以考虑加入更多的TMU单元,因为那时的R350已经是0.13微米的工艺生产了,当然这只是我们的设想,是否有改动还要看ATi的工程师们。 |
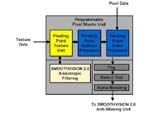 |
| [Pixel Shader渲染详细模块] |
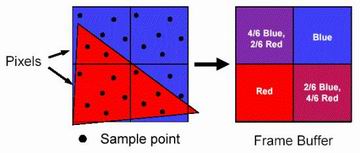
Pixel Shader可以对于16份完全不同的纹理图层上各自进行32次纹理的寻址取样以及64种色彩的操作,其中黄色方块的Floating
Point Texture Unit单元通过显存总线读取到不同精度的纹理数据,然后由Floating Point Address
Processor浮点纹理寻址处理单元在上面搜寻相关的纹理地址,完成之后再由最后的Floating Point Color
Processor色彩处理单元进行渲染。 |
 |
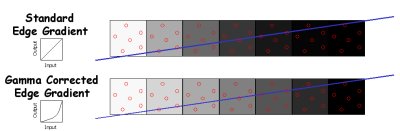
| [PhotoShop等图形软件都受限于0-255范围的色彩调整] |
从16bit的渲染过渡到32bit的渲染已经有相当长的一些年头了,但那些业界 著名的3D领袖们似乎并没有很着急着将32bit的渲染再往更高级一些的渲染方式发展,这显然已经不符合时代的要求,在新一代的显卡中最先由Matrox提出10bit的渲染概念,当然Matrox的新产品Parhelia采用了一些折中的方式来实现高于传统32bit的渲染方式。众如周知,在32bit的渲染中,除去8bit的Alpha渲染之后,仅有24bit的通道来表现颜色,24bit通道大约为16,777,216,我们之前所能做的就是尽量在16.8M的范畴中来调整色彩,然而再往下细分的话,RGB[红+绿+蓝]每个通道可以分到的大约是8bit的精度,也就是大约在0-255之间进行色彩的调整,所以图形工作人员可能常会抱怨无法得到十分纯正的白色或黑色,在一些高精度的图形软件中部分信息的失真及错误的显示都有可能是由此而引起的。 |
| 而Parhelia则大幅度的砍掉Alpha通道所占用的精度,降为2bit,接着提升每一个RGB通道为10bit的bppc,这样虽然总合仍是32bit并符合目前标准的32bit帧缓存储,但实际再通过10bit的RAMDAC还原后的效果的确要比标准的32bit要真实得多,因为这个时候它的通道可以达到0-1023,但Parhelia这样处理是以牺牲Alpha通道来实现的,这在有些时候会让你的游戏在烟雾或者满是硝烟的场面中将不那么真实,也许会出现颗粒感很强,或者透明介质表现力不足的画面,因为此时的Alpha通道只有2bit了,连ID
Software的招牌人物John Carmark都表示Parhelia的2bit Alpha可能不够DoomIII使用,而ATi的R300或nVIDIA的NV30这些全128bit渲染的显卡才是DoomIII这类游戏的最佳选择,当然这个时候32bit的帧缓可能不够用了。 |
| 在计算机的计算中通常我们都需要涉及到浮点的运算操作,简单一点的说浮点的运算操作,实际上就是在计算小数点位置,我们将小数达到32位的运算操作称为单精度的浮点运算,如果达到64位或128甚至更高的话,那么就属于双精度的运算。那么如果一个仅为16bit的浮点运算可以表示的最小数值至最大数值为0.0000000000000001-10,000,000,000,000,000的话那么32bit的浮点运算所能表达的数字值就更大了,难道这样的单通道色彩信息的表现能力还不足以渲染出你所需要的各种颜色嘛?ATi的R300就能做到这样精度的运算。 |
 |
 |
| [车的左边采用的是传统的8bit通道所渲染出来的画面,右边则是16bit通道所渲染出来的画面,可以看到右边的画面明显比左边的干净,少了许多的颜色杂质] |
|
| [在光源与反射的效果上,16bit或更高精度的渲染更加占据优势]] |
|
|
| 但从目前ATi公布的资料来看,似乎并不是真的128bit的渲染,而是96bit的。那么也就是RGBA都各分配24bit的信息通道,至于为什么不是32bit每通道的分配,我们也不得而知,另一方面R300的帧缓存却是可以支持128bit格式的帧缓存储,这样做应该是为了存储性上的方便,可惜的是受限于10bit的RAMDAC,也许96bit的渲染最终也不能完完全全无损的还原到我们的显示器上,同时目前也只有DX9才支持128bit的帧缓存储,OpenGL还没有升级支持。但要知道如果真的有一天实现了全128bit的渲染游戏的话,那现目前的显存带宽都将再次受到严重的挑战,它需要的带宽是32bit格式存储的4条,也许那时我们又将回到30FPS就该觉得满足的时代,所以目前就算应用到128bit浮点精度的渲染应该还是在芯片内,之后会有一些抖动操作去除一些信息这样才能最后再以32bit的格式存放于帧缓存之中,具体情况还有待DX9正式发布以及支持高于8bit通道渲染的游戏发布之后再能清楚。 |
| 另外Pixel Shader还可以实现多目标的信息输出,这在上一代中每一次只能输出一次的目标信息,现在却可以四个一起来,这在一些多纹理应用的游戏中很有用,比如实时实现描边滤镜等特效。另外它也支持双阴影模板的硬件加速。 |

[一次性输出两种完全不同的纹理及光源效果] |