首 页
活动详情
游戏候选区
最新动态
论 坛
游民部落
FPS论坛
魔兽论坛
FIFA论坛
魔力论坛
石器论坛
奇迹论坛
精灵论坛
反恐精英
雷神之锤
魔兽争霸
FIFA足球
魔力宝贝
石器时代
奇迹M U
精 灵
2002~2003年度首届英特尔--新浪明星玩家评选
(以上排名以字母排序)
请问您目前是否拥有自己的电脑?
有电脑
没有电脑
竞争中蜕变的ATi
图形卡的霸主位置总是在几年内轮流由不同的公司占据,无论是从显卡在市场的占有率还是在纯硬件技术的领先上都是如此,由Trident到S3再到3dfx几乎每一家显卡公司都是在自已最风光的顶峰之后立马走向了衰落,到今天这些厂商们要嘛倒闭,要嘛被收购,要嘛低调运行。
三年前当nVIDIA逐步走向了图形卡霸主的位置时候,没有人知道有nVIDIA能在这个位置上坐多久,结果nVIDIA的强势性作风让他们一直高居于这个位置,所以这几年来其它的图形卡公司都过得不怎么精彩。然而大家在提及nVIDIA之余,也会立马就想起市面上唯一还能与它一争长短的另一家公司ATI。
ATI是什么样的公司?它的历兄几乎要比nVIDIA久一倍,它的员工人数几乎要比nVIDIA多一大半,它曾是世界上最大的图形卡OEM供应商,然而这家公司在前几年由于一些决策上的错误使它低调了一些时间,在那段时间内它们的产品开发总是不顺利,Rage128被称之为3代半的显卡,高效和相对速度损失最小的32bit渲染却由于在速度上不及16bit的Voodoo3和TNT2而在那一场显卡争霸战最重要的战斗中失去了最大的优势。
就是Rage128开发的严重延期现象,使得ATi元气大伤在接下来的几年内只能很艰难的与其它的竞争对手竞争,但是从Radeon之后ATi正尝试着逐步走出这段阴影的时期,结果它们也做到了。
目前ATi最大的竞争对手nVIDIA正面临着几年前与ATi同样的情况
1、短期内过多的进入太多不同领域的市场,分散了原本工程师们的开发计划。
2、太大胆的相信TSMC台积电的新工艺掌握程度,结果良品率一直上不去,自身成了白老鼠[当年ATi与今天的nVIDIA采用0.13微米芯片技术一样,第一家与TSMC合作生产当时第一款采用0.18微米技术的图形芯片],nVIDIA的失误再加上ATi自身不断的努力,不被竞争对手打扰的产品周期开发使得在多年后,这年图形业的另一位巨人得以不用老是在追着nVIDIA的脚步,可以扬眉吐气的向全世界大吼一声“We are back!”
前不久ATi的总裁KY Ho率领ATi旗下的工程师们在北京所召开的发布会上,自豪的宣称:“没有一家的图形厂商在从显卡第一宝座上下来之后,还能再重新返回第一的位置,然而今天ATi做到了。”
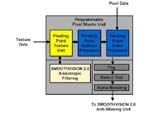
ATi R300的开发背景-ArtX实力的首次体现
ATi旗下的1000多名工程师中有接近一半500人是从事硬件核芯开发,其余500人从事相关的软件或驱动开发。在Radeon8500之后,ATi决定让美西开发小组来开发R300的原型,美西开发小组大家听起来可能会觉得比较陌生,实际上它是在美国西部的ATi分公司的开发小组,它的另一个名字叫做ArtX。
ArtX相信大家是再熟悉不过了,它们原先是一家在美国独立运营的公司,之前并没有什么很大的名气,在承接了任天堂Gamecube的图形核芯开发计划之后一下子向世人展示了它们的低成本高性能的开发理念,内嵌式的显存设计让大家在如何更有效的利用高速显存上又有了新的发展方向。正因为ArtX的出色表现,ATi不惜巨金收购了这一家公司,以壮大自已的研发实力。在收购了ArtX之后,ATi先是利用它们在整合图形技术上的优势推出当时第一款将硬件T&L整合进北桥的逻辑芯片组S1-370TL,然而ArtX加盟ATi的首款产品最终并没有取得成功,个中的原因鲜为人知。
ArtX开发小组的创意再加上ATi原本开发小组的资深经验,于是我们今天的主角R300便诞生了,不过很遗憾的是R300本身并没有加入ArtX在设计Gamecube的Flipper图形核芯时所采用的内嵌式1T-SRAM高速显存,当然这并不是ATi工程师们的错,至于其中的原因我们将在下文中向大家解释,好了现在就让我们走进ATi这一款的翻身力作R300,让我们理解它对于PC用户到底意味着些什么,又带来了些什么。
图:[R300对比规格表]
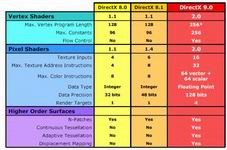
R300与DirectX 9:
R300的正式命名为Radeon9700,用ATi自已的话讲,它是第一款真正支持微软DirectX9的显卡,微软每一代的DirectX API都会选择与一家或者几家的图形卡开发商共同合作,在微软的DirectX会议上,大家彼此提出对于未来图形技术发展的需要,然后由微软统一制定最后的标准。打个比方在DirectX 8中微软提出了一个HOS高阶维面的要求,ATi向微软的DirectX委员会提交了N-Patch的申请,而nVIDIA则提交了RT-Patch的申请,最后微软则将这两种不同的HOS支持都加入到DirectX 8中,所以每一代的DirectX标准其实都离不开微软与各家显卡厂商之间的合作。
每一代的DirectX都有自已的升级标准,例如DirectX 7需要显卡具备并支持硬件T&L单元,DirectX 8需要显卡具备可编程的顶点与像素遮蔽器[Program Vertex Shader、Program Pixel Shader],那支持DirectX9的标准也不例外,需要大致符合如下新特征的标准:
1、 支持更高级的可编程顶点与像素遮蔽器2.0版本[PVS、PPS]
2、 多重目标渲染[支持单Pass最高16级的纹理贴图]
3、 支持高精度Float Point浮点格式的处理以及帧缓存储
4、 双方向式阴影模板硬件生成
5、 Displacement Mapping置换构图法
6、 其余HOS高阶维面[RT-Patch、N-Patch]的升级支持(注:HOS的支持在DX8中就有,DX9只是做了升级,但HOS在游戏中并不普及,所以不算必不可缺的重要特性)
目前能符合以上标准的显卡的的确确只有ATi一家的R300,不用说将来nVIDIA的NV30也肯定能支持DX9的这些标准,但其它的一些新产品诸如Matrox Parhelia、3DLabs的VP10都在某些方面不能完全符合以上的标准。当然我们现在谈论DX9还是为时太早,因为它还需要一段时间才能与我们见面,随带提一下,ATi将R300称之为VPU[视觉处理单元],显然这要比当初的GPU要高出一些档次,新一代的显卡属不属于VPU类型已经注定是下一个图型时期的主流选购意向了。
R300硬件全分析
--R300比上一代更高级的Programs Vertex Shader与Program Pixel Shader
[DX之间的对比表格]
在DX8中,微软提出了Programs Vertex Shader 1.2与Program Pixel Shader 1.1-1.4,微软对于图形发展的可编程性的支持与推动不遗余力,然而在这中间微软却忽略了市场对于显卡功能性的需求,PVS与PPS对硬件与软件都提出了前所未有的严格要求,打个比方如果一款游戏想要全面利用PVS和PPS的话就要放弃一些较为传统的设计方案,但这样又造成了游戏与中低档显卡的不兼容甚至不同显卡在支持PVS和PPS上都有一些不同,所以大部分的厂商只将PVS与PPS做为一种额外的特效来支持,并没有全面的普及。即使这样,微软还是铁了心的发布它们的PVS与PPS,在DX9中PVS与PPS都发展到了2.0版本。先让我们来看看在处理规格上DX8、DX8.1、DX9之间有些什么差别。
很明显,微软公司做了极大的升级调整,Vertex Shaders 2.0相比之前的1.0版本,所能接受的最大处理规格更加的多,并且复杂与精确。比如在DX8体系中对于顶点效果器的编程最大的限制指令长度是128条,然而到了DX9中却升级为256条,实际上这还可以通过Loop缩环回路实现最大1024条指令,更多的指令数处理上升意味着R300可以在同一周期内处理更多的单顶点光源或者更多的矩阵转换或者实现更多精彩的效果,当然对于越来越懒惰的PC游戏开发商们来说,256条指令或者1024条指令对于它们来说并不会有太多的影响,所正PC上的3D游戏看来看去都是那样的画面不是嘛?除了顶点效果器的指令长度和常数指令有了较大的提升之外,2.0版本的Vertex Shader的另一大特色是增加进了流程的控制,包括了上面提到的循环、跳转、子程序调用这些类似于C语言中很基础的流程方式,更具体的还有ADD,DP3,DP4,EXP,FRAC等等[有兴趣的话可以参考ATi的HardwareShading_2002_Chapter3-1.pdf白皮书],这些编程的函数性使它看起来更像一颗可以编程的图形芯片,不是嘛?因为在以前的Vertex Shader版本中,如果想要将不同的纹理与不同的光源混合在一起的话就需要单独写一段Shader效果器的程序来,这意味着每一次混合就要调用一段的程序代码。而在Vertex Shader 2.0中却不需要这样用,开发者只需将色彩,方向,光源等等这些自定义值写入子程序中直接调用即可。
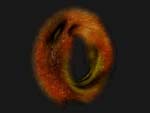
[ATi提供的,演示动物茸毛的Demo,通过在子程序中写入自定义值即可实现最后的生成效果,其中包括了Fin皮肤鳍状形体与茸毛细节纹理]
[Fuzzy茸毛效果的放大图,据ATi的工作人员表示在三年前当时最顶级的显卡完成这样的渲染需要耗时大约十几个小时,而ATi现在能做到Real-Time实现渲染]
1、[先将正常的多边形依据每条边缘法线的方向进行一定的移动操作---称之为Shell外壳生成]
2、[增加额外更多的多边形同样依据边缘法线的方向进行突出伸长的步骤---称之为Fins鳍状生成]
3、[将第一步Shells+第二步Fins鳍状]
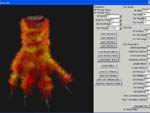
4、[ATi提供的生成调用工具软件]
nVIDIA在GeForce4 Ti系列加入了两条的Vertex Shader流水线,这样当3D程序在GF4 Ti的2个Vertex Shader进行三角形的顶点坐标转换工作的时候,相较传统的T&L就能节省大约一半的时间,依我们前文中提到每个顶点的转换需要四条指令的运作。
[实际上一个三角形的生成就是顶点坐标转换的乘法运算]
而ATi为R300加装了4条的Vertex Shader流水线,这样只要在一个单周期时钟频率,也就是1MHz内4条流水线同时开动,就能完成一个三角形顶点位置的转换,这意味着Radeon9700拥有325M/s的三角形生成能力,当然这样的处理也包括128bit的双精度诉求,GeForce4 Ti4600大约为136M/s,GeForce3 Ti500为60M/s,Radeon 8500则是68M/s。
[ATi R300的4条
Vertex Shader流水线]
[Vertex Shader的
详细流水结构]
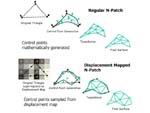
[新一代的N-Patch概念
Truform 2.0更加的灵活]
每条流水线中还包含了一个32bit的标量处理器与128bit的矢量处理器,简单一点的说就是数量是对数据处理的选择采用一个一个的数据不同值的对比运算处理,矢量是对一组数据同时处理的方式负责诸如坐标X,Y,Z,W等组合型的数据流,在Vertex Shader ALU处理中,除了Loop Counter这项操作是用标量方式之外,大部分都采用矢量的处理方式。
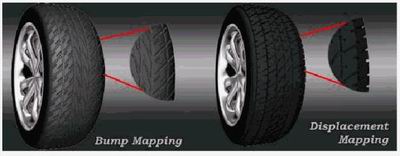
ATi从R200开始就力推它们的N-Patch特性,虽然这是一项任重而道远的工作,但ATi显然还是乐此不疲。在DX9也包括了Truform 2.0的支持,它在操作方法上与上一代的Truform没有太多的不同,只是在其中的关键操作Tessellation棋盘型嵌入上显得更加灵活,之前的Radeon8500限定了Truform只能采用在固定的8个等级中进行调整的方案,就好像如果设定了4级的Truform的话那么无论远景或是近景都将一律的采用4级的嵌入,这就造成了在一些游戏中出现了模型的变形与不符合现实的画面出现,例如在Serious Sam中的变形的圆形枪体,在Truform 2.0中将不会再出现这种现象,它会根据3D场景的远近自适应的判断该用哪一种等级又或者不采用嵌入的操作。除此之外新的TruForm中还包含了Displacement Mapping功能,对于此功能之前我们在介绍Matrox Parhelia的技术文档中有关相当的描述在此就不再重复,但是我想提出的一个看法是Displacement Mapping并不真的可以像Matrox所说的那样,可以完全代替三角形构模法。实际上它很难独立地做出精细的立体模型,所以我更偏向ATi对于Displacement Mapping的定义:能够在3D对象与外形的表面上提供更多的控制,从特殊种类贴图取样值来进行顶点位置的修改,视觉效果类似Bump Mapping,但是比Bump Mapping更逼真与细致。
[ATi对于Displacement Mapping用途的定义与Matrox有些不同]
OK,现在轮到ATi R300的另一个精髓部分了--Pixel Shader,很可惜Pixel Shader 2.0似乎并没有Vertex Shader 2.0进步的那么大,它并不支持流程控制,所以对于编程人员来说,应用它是件复杂的工作过程,但是对我们最终用户来说却没有什么不同之处。
[Pixel Shader流水线]
R300始无前例的整合了8条像素Pipeline流水线,这在半年前还是不少人梦想中的事,现在却成为了事实。每一条流水线上只包含了一个的纹理元素渲染器,这样ATi在单纹理渲染与多层纹理渲染的理论性能值上是一样的,可能你会对这样的设计在外理多层纹理时的性能是否相较当前流行的单流水线双纹理单元的性能的提升持有一些怀疑的意见,实际上这样做在处理多层纹理时的性能的确提升的并不明显,但这并不是ATi的错,而是受限于当前的存储介质。如果ATi再增加一个纹理元素渲染单元的话,256bit的显存位宽将无法满足纹理传输的需要,所以装了也是白装。当然我们认为如果再加多一个纹理渲染TMU单元的话,对于Die的空间或许也是一个挑战。所幸的是ATi同样可以通过以循环的方式进行重复性的纹理贴图,这在上一代的显卡中已经被广泛的采用,所以并不用太担心只有单个的纹理渲染单元会耗掉你太多的渲染时间,我们认为如果ATi在将来设R350的时候,如果采用了DDRII的显存模块,那么将可以考虑加入更多的TMU单元,因为那时的R350已经是0.13微米的工艺生产了,当然这只是我们的设想,是否有改动还要看ATi的工程师们。
[Pixel Shader渲染详细模块]
Pixel Shader可以对于16份完全不同的纹理图层上各自进行32次纹理的寻址取样以及64种色彩的操作,其中黄色方块的Floating Point Texture Unit单元通过显存总线读取到不同精度的纹理数据,然后由Floating Point Address Processor浮点纹理寻址处理单元在上面搜寻相关的纹理地址,完成之后再由最后的Floating Point Color Processor色彩处理单元进行渲染。
[PhotoShop等图形软件都受限于0-255范围的色彩调整]
从16bit的渲染过渡到32bit的渲染已经有相当长的一些年头了,但那些业界 著名的3D领袖们似乎并没有很着急着将32bit的渲染再往更高级一些的渲染方式发展,这显然已经不符合时代的要求,在新一代的显卡中最先由Matrox提出10bit的渲染概念,当然Matrox的新产品Parhelia采用了一些折中的方式来实现高于传统32bit的渲染方式。众如周知,在32bit的渲染中,除去8bit的Alpha渲染之后,仅有24bit的通道来表现颜色,24bit通道大约为16,777,216,我们之前所能做的就是尽量在16.8M的范畴中来调整色彩,然而再往下细分的话,RGB[红+绿+蓝]每个通道可以分到的大约是8bit的精度,也就是大约在0-255之间进行色彩的调整,所以图形工作人员可能常会抱怨无法得到十分纯正的白色或黑色,在一些高精度的图形软件中部分信息的失真及错误的显示都有可能是由此而引起的。
而Parhelia则大幅度的砍掉Alpha通道所占用的精度,降为2bit,接着提升每一个RGB通道为10bit的bppc,这样虽然总合仍是32bit并符合目前标准的32bit帧缓存储,但实际再通过10bit的RAMDAC还原后的效果的确要比标准的32bit要真实得多,因为这个时候它的通道可以达到0-1023,但Parhelia这样处理是以牺牲Alpha通道来实现的,这在有些时候会让你的游戏在烟雾或者满是硝烟的场面中将不那么真实,也许会出现颗粒感很强,或者透明介质表现力不足的画面,因为此时的Alpha通道只有2bit了,连ID Software的招牌人物John Carmark都表示Parhelia的2bit Alpha可能不够DoomIII使用,而ATi的R300或nVIDIA的NV30这些全128bit渲染的显卡才是DoomIII这类游戏的最佳选择,当然这个时候32bit的帧缓可能不够用了。
在计算机的计算中通常我们都需要涉及到浮点的运算操作,简单一点的说浮点的运算操作,实际上就是在计算小数点位置,我们将小数达到32位的运算操作称为单精度的浮点运算,如果达到64位或128甚至更高的话,那么就属于双精度的运算。那么如果一个仅为16bit的浮点运算可以表示的最小数值至最大数值为0.0000000000000001-10,000,000,000,000,000的话那么32bit的浮点运算所能表达的数字值就更大了,难道这样的单通道色彩信息的表现能力还不足以渲染出你所需要的各种颜色嘛?ATi的R300就能做到这样精度的运算。
[车的左边采用的是传统的8bit通道所渲染出来的画面,右边则是16bit通道所渲染出来的画面,可以看到右边的画面明显比左边的干净,少了许多的颜色杂质]
[在光源与反射的效果上,16bit或更高精度的渲染更加占据优势]]
但从目前ATi公布的资料来看,似乎并不是真的128bit的渲染,而是96bit的。那么也就是RGBA都各分配24bit的信息通道,至于为什么不是32bit每通道的分配,我们也不得而知,另一方面R300的帧缓存却是可以支持128bit格式的帧缓存储,这样做应该是为了存储性上的方便,可惜的是受限于10bit的RAMDAC,也许96bit的渲染最终也不能完完全全无损的还原到我们的显示器上,同时目前也只有DX9才支持128bit的帧缓存储,OpenGL还没有升级支持。但要知道如果真的有一天实现了全128bit的渲染游戏的话,那现目前的显存带宽都将再次受到严重的挑战,它需要的带宽是32bit格式存储的4条,也许那时我们又将回到30FPS就该觉得满足的时代,所以目前就算应用到128bit浮点精度的渲染应该还是在芯片内,之后会有一些抖动操作去除一些信息这样才能最后再以32bit的格式存放于帧缓存之中,具体情况还有待DX9正式发布以及支持高于8bit通道渲染的游戏发布之后再能清楚。
另外Pixel Shader还可以实现多目标的信息输出,这在上一代中每一次只能输出一次的目标信息,现在却可以四个一起来,这在一些多纹理应用的游戏中很有用,比如实时实现描边滤镜等特效。另外它也支持双阴影模板的硬件加速。
[一次性输出两种完全不同的纹理及光源效果]
全新的
SmoothVision 2.0
ATi在上一代产品中Radeon8500中,所设计的FSAA全屏抗锯齿与Anisotropic filtering各向异性过滤的作用一直为人所批评,其中包括了Radeon8500的FSAA实际上只是暴力式OGSS的另一个名称和示例,Anisotropic Filtering各向异性过滤只能在双线过滤下起作用,如果开启的是三线过滤再同时打开各向异性过滤的话,那么三线过滤会自动降为双线过滤。
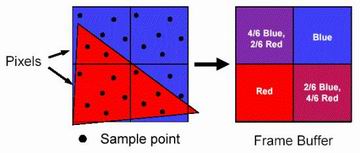
那么SmoothVision 2.0会有些什么进步呢,首先我们还是先来看看它的FSAA技术,在FSAA的世界里有两种主要的概念SuperSampling与MultiSampling超采样与多采样,超采样通常需要在后台进行高于实现显示分辨率很多的分辨率或将同一帧画面渲染数次之后再进行子像素的采样,可以是OGSS方式或RGSS方式。但目前越来越少人喜欢用这种方法进行FSAA处理了,原因很简单太消耗性能与显存带宽了。那么MultiSampling怎么样呢,它是通过将同样的一帧的画面只渲染一次,但分别的存储于多个的帧缓区内,进行各自的混合子像素操作,常用的方法除了上述的OGMS与RGMS之外还有PJMS[一种子像素采样位置不固定,可自行编程定义位置的方法],虽然MultiSampling要比SuperSampling快上很多,但是它却无法正常的抗锯齿渲染Alpha的非多边形画面,比如植物的叶子。造成这种现象的原因是Multi-Sampling只能识别出一帧画面中的前景与后景两种显而易见的画面,而对于Alpha这样夹在半中间的通道信息很难识别的出来,这可能是由于这种采样方法的通道表现能力不足所引起的。
但R300却可以修正这个问题,另外R300的FSAA采样分为了2x、4x、6x,这些指标所表示的是在每一个像素Block中所安放的采样点的数量,采样点越多,所能收集到的像素参考颜色信息也就越多,自然最后的效果也就越好了。这样的设计同时存在于SuperSampling与MultiSampling中[没错,R300中也包含了SuperSampling,两种FSAA的关系就会像现在ATi驱动中的Quality与Performance设定一样]。R300在SuperSampling情况下,会将像素的颜色值的采样点归类,比如在A像素内拥有1-6个的采样点,像这个采样点最终都取得到同样的一个色值,这样R300就不会6次的存储同样一个色值的采样点以确定这个像素,只是干脆直接只存储一次这些色值的赋值数即可。这样的方法被证实了在大量的游戏中都十分的有效。因为每个3D物体或场景中颜色的过滤都不是完全突变的。
[采样点的安放位置,如有需要, 就对其中每个采样点的色值进行加权计算后存入帧缓,它能以每个像素中各种色值所占多少比例的方式进行存储。]
在MultiSampling中由于存在两种“场”―前后景,所以实际上它要比SuperSampling多做一项Z-Buffer对比的工作,以确定哪些场是属于前景哪些场是属于后场,而ATi R300中在这部分对比时也引入了它们引以为豪的Hyper-Z III概念,可以对需要对比的Z-Buffer数据进行2:1或4:1的压缩这看起来能使它的性能再一步的得到提升。
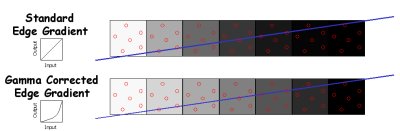
SmoothVision的另一项改进之处在于它们设计了一个专利的Gamma Correction伽玛纠正技术。伽玛纠正技术是一项被在实际显示中非线性响应特征中被广泛使用的技术。换句话说如果你传寄出一个“2”的亮度信息至显示器上,那么最终这个像素并不会显示出相当于两个“1”的亮度,这就需要由Gamma曲线响做一些的纠正,目前大部分的游戏或其它3D软件都提供了亮度响应的设定,但ATi却将这项技术的应用整合进了FSAA中,也就是说它可以自动的平滑一些闪烁的多边形边缘,能使色彩值看起来更加的自然。
[动态伽玛的纠正]
[SmoothVision2.0的效果]
最后需要提的是,R300终于改正了在各项异性过滤下只能开启双线性过滤的问题,现在我们又可以用回三线性过滤+各项异性纹理过滤了。
新一代的VIDEOSHADER技术
在新一代的R300中,ATi还提出了一套FullStream技术,这项技术实际上还被加入了Radeon9000的产品中,但很可惜就目前为此我们对此所知甚少,ATi只告诉我们是利用Pixel Shader来加速完成的,它能对一些杂讯的画面进行过滤还原,而且在播放视频流的时候,除了传统的Bob和Weave反交错技术之外,还有一套全新的动态可编程自适应的反交错技术,称之为增加型的动态De-Interlacing,甚至还可以实现一此视频画面的过滤编缉效果比如像模糊,压纹,描边等等,要知道这些也都是实现完成的。
VIDEOSHADER中的核心技术Fullstream流程运作
1、 标准的原始视频帧
2、 对画面进行量子化的画面分析
3、 像素优化过滤
4、 实现最终的增效画质
Fullstream需要与Real Player等第三方软件商合作方能发挥出效用,但我们现在还没有拿到特别版的Real Player。
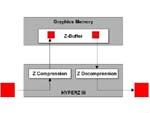
Hyper-Z III、256bit显存总线、AGP 8X接口介绍
自从在第一代Radeon256发布时所带来的Hyper-Z开始,ATi就在每一代的显卡中都加入这项节省显存带宽的技术,可以这么说每一代相较上一代都有一定的进步,但都不是非常大的跨越性进步。
Hyper-Z III中仍旧包含了三项功能:Hierarchical Z、Fast-Z Clean、Z Compression
Fullstream需要与Real Player等第三方软件商合作方能发挥出效用,但我们现在还没有拿到特别版的Real Player。
[Hierarchical Z]
Hierarchical Z,我们已经介绍过了,它是通过在芯片内部对Z-Buffer先进行金字塔式的分级,之后再进行比较得出一些较为方便进行对比的初级数据,然后再进行传统的Z-Buffer寻址。具体的说在Hierarchical Z中,它先将屏幕上的全像素以8x8分为基本像素块,然后再以2个像素为准在其中分为2x2标准的16个像素块,然后在每一个2x2的像素块中取出其中最大的一个Z轴数据,这样每一个原先全屏中像素块中的最大Z轴数据都取出后再放在一起形成一个新的像素Block,这样比到最后将每一组的最后生成值先进行对比,如果该项Z轴值比较大那么就表示离我们较远可以不必再做重复的渲染,如果有疑问就再进行下一级数据的对比。在Radeon8500中标准像素块是4x4像素的。而R300中则升级为2x2像素,显得更小,也更精确。
[Fast-Z Clean]
Fast-Z Clean,据说会比一般的Z-Buffer Clean清除快上64倍,因为它需要写入的清除资料要少得多。
[Z Compression]
Z Compression,有效的Z数据的压缩和解压缩,对于Pixel Shader中的FSAA操作特别的有帮助。
[AGP总线对比]
ATi
为
R300
还带来了
AGP 8X
与
256bit
的全新总线传输及显存位宽界面,如果以每个顶点至少需要传输
7K
的数据量来看,从系统传通过
AGP
总线传输到显卡芯片上的通道也不过才
1GB/s
而已,但如果在
3D
应用中顶点数据超过百万个或更多的话那么
AGP
总线将受到严峻的挑战,虽然
AGP 8
经的到来能为显卡总线稍缓解一些的压力,但我不认为这能解决根本的问题,因为顶点数据量随着
Vertex Shader
的普及将来越来越庞大。
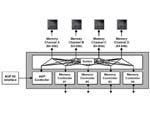
[显存交叉转换应用界面]
ATi所设计的R300拥有大约256bit的总线位宽,这在上文我们已经提及过了,再搭配上310MHz的显存频率,大约最后我们可以得到接近20GB/s的显存带宽,这在现在来看无疑是显存带宽最高的一款产品,更为有意思的是ATi也引用了nVIDIA的交叉式内存控制器。同样也设计了四个四通八达的内存控制器界面,在平时它们将256bit分成4个64bit的传输通道进行传输工作,在碰到大量数据时再自行合并,在较为细碎的3D游戏场境中,这要比一条独立的256bit通道有用得多。
发表评论